[Preview] Half-Width and Full-Width Characters
October 6, 2024
Those of us who live and speak English will probably never think about how characters are encoded which is how characters such as the
very letters you see in the screen are represented by being given some number like 65 for ‘A’ in ASCII which takes 1 byte to be represented
such as a char in C.
I was not aware of the existence of full-width and half-width characters till the friend asked me to briefly explain the highlevel information about the difference in representing the characters. For those like me who weren’t aware that the Japanese mix between zenkaku (full-width) and hankaku (half-width) characters, look at the image below or visit this webpage: https://mailmate.jp/blog/half-width-full-width-hankaku-zenkaku-explained

Based on the article I shared, half-width characters takes up 1 byte while full-width characters takes up 2 bytes (also can be called double byte character). I do believe this depends on the encoding used. For me, the most obvious distinction between half and full width characters is how much graphical space it consumes as evident from both the image above and below:
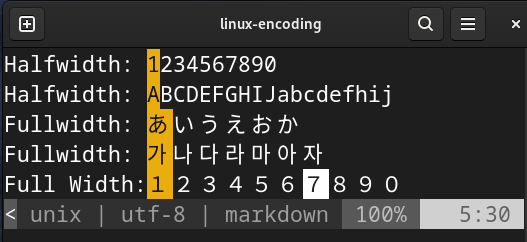
Full and Half Width encoded on UTF-8 as seen through Vim
While I have read and typed Korean during my younger years when I was forced to learn Korean, it never clicked to me how much space Korean
takes up graphically. It is obvious in hindsight but it was nonetheless interesting. Taking a look at the size and bytes encoding, we can
see that number 1 in UTF-8 encoding takes 1 and 3 bytes for half-width and full-width character repsectively
$ stat -c "%n,%s" -- halfwidth-utf8.txt fullwidth-utf8.txt
halfwidth-utf8.txt,1
fullwidth-utf8.txt,3
One confusion I had was understanding what the difference between UTF-8 and UTF-16 and the following excercise helped me understand this:
- UTF-8 encodes each character between 1-4 bytes
- UTF-16 encodes each characters between 2-4 bytes
UTF-8 and UTF-16 as you can tell are variable length meaning they take up more or less bytes depending on the character being encoded. We can
see this by comparing the number 1 arabic numeral v.s. 一:
$ stat -c "%n,%s" -- halfwidth-1.txt chinese-1.md
halfwidth-1.txt,1
chinese-1.md,3
In UTF-8, 1 takes up 1 byte which is unsurprising as ASCII has great advantage in UTF-8 compared to other Asian languages.
Note: Do not attempt to display UTF-16 encoded files on the terminal without changing your locale (or whatever it is called). It will not display nicely. Vim on my machine will automatically open the file as UTF-16LE.
Let’s inspect the contents of the files between Half character 1 and Full Byte Character 1 in HEX:
$ cat halfwidth-1.txt; echo ""; xxd halfwidth-1.txt; cat fullwidth-1.txt ; echo ""; xxd fullwidth-1.txt 1 00000000: 31 1 1 00000000: efbc 91 ...
As we can see, the half-width character 1 in UTF-8 is represented as 0x31 meaning only one byte would be required. However, a full-width
digit 1 is represented as 0xEFBC91. Now let’s compared this with UTF-16:
$ cat halfwidth-utf16.txt; echo ; xxd halfwidth-utf16.txt; cat fullwidth-utf16.txt; echo; xxd fullwidth-utf16.txt
1
00000000: 0031 .1
�
00000000: ff11 ..
Note: To view UTF-16 on VIM run on command mode (i.e. press esc to exit current mode and press : to enter command mode): e ++enc=utf-16be fullwidth-utf16.txt
As expected, UTF-16 represents code points in the upper range very well where we now see 1 (full-width 1) being represented with only 2 bytes unlike the 3 that was required in UTF-8.
Though the same cannot be said for code points in the lower range such as our half-width digit 1 which now takes 2 bytes by appending 0x00 to its hex representation.
I will be writing a more detailed look into encoding at my blog in the coming days. This is just a quick preview.